A Better Way to do Case-Control Studies
Created/Modified: 2015-01-12/2019-02-06
Case-control studies are used as a cheap alternative to population studies. The ideal way to study cell phones and cancer would be to randomly assign a large number of people to either "cell-phone user" or "non-cell-phone user" groups and then check in with them once a year for a couple of decades to see what the rates of various diseases are. Because things like brain cancer are very rare, the number of people in such a study would have to be huge, which gets very expensive.
Case-control studies instead do the following:
- Find a bunch of entities that have instances of the effect you are interested in. These are the "cases". They are people, typically, and the effect is some disease.
- Find an equal or greater number of entities that are matched with your cases in every respect except the factor(s) that you think might be the causes of the effect you are interested in. These are the "controls".
- Compare the size of the purported causes in the two populations and see if they are significantly different.
- Publish before doing any further investigation, sanity-checking, or corrections for multiple experiments.
- Have your institution give out the most hyperbolic press-release that your conclusions can be tortured into confessing support for, because torture works so well
Admittedly, the last two steps are not strictly required for a well-designed case-control study. They are just extremely popular.
Alternatively, you could track how much a large number of people use their cell phones over a couple of decades until a few of them get brain cancer, and hope heavy cell phone users happen to be pretty much the same in all respects to the people with lower usage. A few moments thought will suggest this isn't very likely: younger people, for example, tend to use cell phones more. There are a lot of things that correlate with heavy cell phone use.
To fix that problem, you could put together a pair of matched populations: groups that are as similar as possible in every respect except for cell phone use. This still has the problem of requiring a huge number of people, becaused the effect you're looking for is almost always going to be rare.
Case control studies flip the script: instead of recruiting people at the start of the study, they recruit them at the end. Instead of finding a hundred thousand people and waiting twenty years for fifty of them to get brain cancer, why not recruit a few hundred people with brain cancer and look backward to see if they used their cell phones more than people who didn't get brain cancer. By selecting people who already exhibit the rare effect, we seem to be able to get way more satistical power for our research dollar.
But nothing is free: case control studies are a labyrinth of hidden causes and are easily subject to extreme abuse via what seem to be quite trivial choices.
That very nice article I've linked above from 538 takes the case-control results from Swedish case control studies that claim to show a relationship between cell phone use and brain cancer, and applies them to the American population over the past couple of decades. Since cell phone use has increased dramatically in the US over that time, we can compute an expected increase in the rare brain cancer that the Swedes say is increased by cell phone use, and we can see trivially that no such increase has occurred.
Ergo, cell phones don't cause brain cancer.But why would anyone believe they did in the first place?
The problem with case-control studies is that the "case" popultion and the "control" population differ in all kinds of ways, and there is no reason to believe you will have matched them so precisely as to even out all the possible causes except the one you are interested in. To attribute all the difference to that one cause is therefore wrong.
There are ways around this, which I'll go into below, but first let's look at the dynamics of how it happens.
To illustrate it I wrote a little Python code that constructs two populations with ten characteristics, one of which is just a tiny bit different between the two. The difference is undetectable statistically, but it is enough to result in a large apparent difference between the case population and the control population in terms of their exposure to a particular cause. That is: an undetectably small random variation between the two populations actually accounts for all of the difference.
import numpy as np import random import scipy.stats.mstats # a bunch of characteristics with mean 10 and width 5 fMean = 10.0 fWidth = 5.0 nCharacteristics = 10 # one characteristic is going to have a trivial boost # in the case population, just 'cause randomness happens fCorrelation = 1.05 # three match criteria, three possible "causes" nTestCriteria = 3 nMatchCriteria = 3 nPatients = 500 nControls = 2*nPatients for nShots in range(0, 100): lstIndices = range(0,10) random.shuffle(lstIndices) lstPatients = [] for nI in range(0, nPatients): lstPatients.append(np.random.normal(loc = fMean, scale = fWidth, size=nCharacteristics)) for nIndex in lstIndices[-nTestCriteria:]: # causes are tweaked lstPatients[-1][nIndex] *= fCorrelation lstControls = [] while len(lstControls) < nControls: lstTest = np.random.normal(loc = fMean, scale = fWidth, size=nCharacteristics) for lstPatient in lstPatients: nCount = sum([abs(lstTest[nI]-lstPatient[nI]) < 1 for nI in lstIndices[0:nMatchCriteria]]) if nCount == nMatchCriteria: # match on uncorrelated criteria lstControls.append(lstTest) break lstRatio = [] # odds of rare events are based on tails of distributions! for nIndex in lstIndices[-nTestCriteria:]: nPatientCount = 0 for lstPatient in lstPatients: if lstPatient[nIndex] > fMean+2*fWidth: nPatientCount += 1 nControlCount = 0 for lstControl in lstControls: if lstControl[nIndex] > fMean+2*fWidth: nControlCount += 1 lstRatio.append((float(nPatientCount)/nPatients)/(float(nControlCount)/nControls)) nJMax = 0 # now take the BIGGEST difference in effect! fRatioMax = 0 for (nJ, fRatio) in enumerate(lstRatio): if fRatio > fRatioMax: nJMax = nJ fRatioMax = fRatio # compare the distributions... are they different? nJMax -= -nTestCriteria lstPatientData = [] for lstPatient in lstPatients: lstPatientData.append(lstPatient[nJMax]) lstControlData = [] for lstControl in lstControls: lstControlData.append(lstControl[nJMax]) fT, fProb = scipy.stats.mstats.ttest_ind(lstPatientData, lstControlData) print fRatioMax, fT, fProb
This is an illustrative cheat, nothing more. I could have built a fancier model but this is sufficient to make the point.
The results of the simulation are shown below:
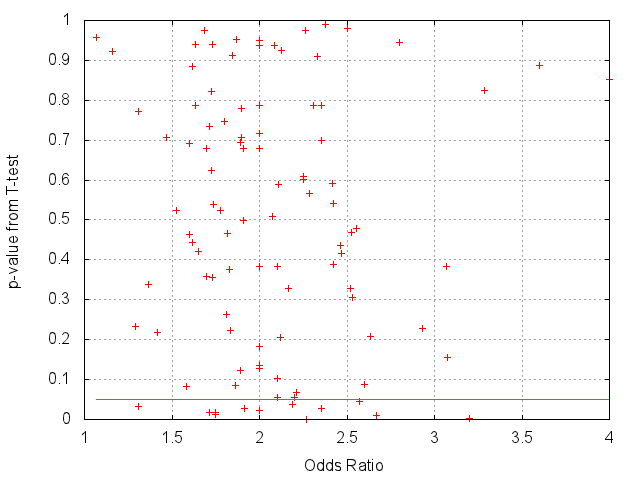
The point is that with an undetectably small tweak to the underlying distribution (the T-test p-values are almost all > 0.05) it is trivially easy to get factors of two or more difference between case and control groups.
This is possible in part because I've allowed multiple possible causes and selected and reported on the one that showed an effect. This is a criminally bad thing to do, utterly illegitimate and wrong. If you're going to do it, you need to a) define the categories of cause beforehand and b) correct all your p-values for the fact that you've gone on a fishing expedition. The odds of something being correlated with your effect are as near as anything to a certainty. The more different things you look at as "possible causes" the more likely it is that you will find one that is correlated by chance. Likewise, the more effects you look at--especially when you start taking sub-sets of your "case" population--the greater the odds of finding a cause that seems to be important between the two groups, but which is just the result of chance.
The importance of the stunt I've pulled here is that by any ordinary statistical standard (and the T-test is as ordinary as you can possibly get) the distributions are not different, but the specific procedure used to tease out the effect results in an apparently dramatic consequences. Statistically identical distributions are generating factors of two or more differences!
This is another way of saying: if you need a case-control study to detect the effect you are looking for, it is probably so small as to be irrelevant to public policy. The money spent on all those case-control studies on cell phones and brain cancer would have saved far more lives had it been spent on almost anything else: auto safety, anti-smoking campaigns, etc.
One of the reasons I don't work in radiotherapy any more, after a brief and productive stint in the field in the early '90's, is that I realized all the money we were spending would be far better put into anti-smoking and other campaigns against the small number of things we knew pretty well caused cancer, instead of marginally improving radiotherapy treatment, which was a) already pretty good and b) showed no significant likelihood of improving much. And in fact, in the ensuing quarter century radiotherpy has continued to be about as effective as it was back in the day.
There are ways case-control studies can be improved to generate results that are more reliable guides to reality. In particular, any decent case-control study should look at exactly one possible effect, or correct very aggressively for multiple experiments. It is hard to overstate how rapidly the statistical power of data decreases as hypotheses multiply, particularly if they are allowed to work in combination, or if the data are sub-setted, so instead of looking at "brain cancer" you end up looking at "this particularly rare form of brain cancer".
Secondly, additional non-causal variables should be investigated that have similar scope to the potentially causal ones, and their distributions should be analyzed and reported alongside the purportedly causal ones. Ideally this should be done blindly.
That is, if you're investigating cell phone use and brain cancer, you should also question participants on how often they talk to their mother, or how often they go out with friends, or what their favourite colour is, and so on. Everything is correlated (or anti-correlated) with everything else, of course, so it'll be difficult to find truly independent variables... which should give you pause when executing a hyper-sensitive test for correlations. Because maybe cell phone use correlates with how often you talk to your mother, or how often you go out with friends, or what your favourite colour is (seriously: colour preferences exhibit age and cultural differences that could easily correlate with cell phone use.)
By measuring and reporting nominally unrelated variables, it is possible to show the actual significance of the purported effect: "brain cancer is more strongly correlated with how often you go fishing than how often you use your cell phone" is a much less compelling, but much more honest, way to report the results of case control studies. That is: how does the "effect of the cause" compare to "the effect of these other three-to-five things that we really doubt are causal?" If there isn't a big difference, if the nominally causal factor clearly belongs to the distribution of non-causal factors, there is likely no effect.
Thirdly, in the "Methods" section, the rate at which case-control studies produce results that are later shown to be non-effects should be mentioned. A simple sentence like, "Case-control studies have been used in this area of research for the past 20 years. We have found 253 studies in the literature. Only three of them identified effects that were later confirmed by more direct forms of investigation."
If you expect me to believe a result, you need to show me that the method you are using has a good track record of confirmed results in the past. It is true that because of their hyper-sensitivity it will be very difficult to confirm many results from case-control studies by other means, but again: that suggests perhaps redirecting scarce research funding toward areas that have a big enough impact on human life to actually measure.
Fourthly: commit to publishing all results, and get a commitment from your institution's PR people to make the same amount of noise when you find no association as when you do find an association. Put that message, "New study shows no correlation between cell phone use and scurvy!" out there. Try to ensure the same amount of money is spent promoting negative results as positive. Yeah, I know, I'm into the realm of total fantasy here.
Finally: case-control studies should where possible focus strongly on the dose-response curve. In the absence of randomized controlled trials, the dose-response curve is by far the best indicator of causation. If the effect can be graded by levels of severity then the level of severity should be correlated with the level of the cause. If it is not, then the results are probably noise. This may not be possible in all cases, but when it is, not doing it is inexcusable.
Case-control studies do have a use in guiding future research, but they are so limited in their power to draw causal inferences that they should never be used to imply causation without a strong dose-response result. This review is rather more generous to them than I am. I am not aware of any research into how often case-control studies are confirmed on follow-up, and any evidence-based researcher (and what other kind is there?) should be bothered by that.
Here is a nice example of a case-control study that doesn't do everything wrong. They have a single hypothesis, they have a causal account, they do what they can to poke at their results within the limits of their data, and they don't draw grandiose conclusions (I'd like to see the press release associated with the work, though, which probably says something about mothers taking anti-depressants killing babies.)
Even so, tests that are hyper-sensitive to correlations should come with an outsized warning regarding the lack of correlation between correlation and causation, and whenever you read about a case-control study you should think, "This is more likely than not due to random chance and poor research methods, and even if the effect is real it is so small they had to use a test that was hyper-sensitive to correlations to find it, and in any case they don't show any dose-response data so it doesn't constitute more than the tiniest incremental evidence in favour of the proposition under test."